Professional Data Engineer on Google Cloud Platform
Question 161
You need to store and analyze social media postings in Google BigQuery at a rate of 10,000 messages per minute in near real-time. Initially, design the application to use streaming inserts for individual postings. Your application also performs data aggregations right after the streaming inserts. You discover that the queries after streaming inserts do not exhibit strong consistency, and reports from the queries might miss in-flight data.
How can you adjust your application design?
Re-write the application to load accumulated data every 2 minutes.
Convert the streaming insert code to batch load for individual messages.
Load the original message to Google Cloud SQL, and export the table every hour to BigQuery via streaming inserts.
Estimate the average latency for data availability after streaming inserts, and always run queries after waiting twice as long.
Answer is Estimate the average latency for data availability after streaming inserts, and always run queries after waiting twice as long.
The data is first comes to buffer and then written to Storage. If we are running queries in buffer we will face above mentioned issues. If we wait for the bigquery to write the data to storage then we won’t face the issue. So We need to wait till it’s written tio storage
Business owners at your company have given you a database of bank transactions. Each row contains the user ID, transaction type, transaction location, and transaction amount. They ask you to investigate what type of machine learning can be applied to the data.
Which three machine learning applications can you use? (Choose three.)
Supervised learning to determine which transactions are most likely to be fraudulent.
Unsupervised learning to determine which transactions are most likely to be fraudulent.
Clustering to divide the transactions into N categories based on feature similarity.
Supervised learning to predict the location of a transaction.
Reinforcement learning to predict the location of a transaction.
F. Unsupervised learning to predict the location of a transaction.
Answer is B-C-D
Fraud is not a feature, so unsupervised, location is given so supervised, Clustering can be done looking at the done with same features.
Say the model predict a location, guessing US or Sweden are both wrong when the answer is Canada. But US is closer, the distance from the correct location can be used to calculate a reward. Through reinforcement learning (E) the model could guess a location with better accuracy than supervised (D).
Your company has hired a new data scientist who wants to perform complicated analyses across very large datasets stored in Google Cloud Storage and in a Cassandra cluster on Google Compute Engine. The scientist primarily wants to create labelled data sets for machine learning projects, along with some visualization tasks. She reports that her laptop is not powerful enough to perform her tasks and it is slowing her down. You want to help her perform her tasks.
What should you do?
Run a local version of Jupiter on the laptop.
Grant the user access to Google Cloud Shell.
Host a visualization tool on a VM on Google Compute Engine.
Deploy Google Cloud Datalab to a virtual machine (VM) on Google Compute Engine.
Answer is Deploy Google Cloud Datalab to a virtual machine (VM) on Google Compute Engine.
Cloud Datalab is **packaged as a container and run in a VM (Virtual Machine) instance.**
VM creation**, running the container in that VM, and establishing a connection from your browser to the Cloud Datalab container, which allows you to open existing Cloud Datalab notebooks and create new notebooks**. Read through the introductory notebooks in the `/docs/intro` directory to get a sense of how a notebook is organized and executed.
Cloud Datalab uses **notebooks instead of the text files containing code. Notebooks bring together code, documentation written as markdown, and the results of code execution—whether as text, image or, HTML/JavaScript**.
Reference:
https://cloud.google.com/datalab/docs/quickstarts
You are building a model to predict whether or not it will rain on a given day. You have thousands of input features and want to see if you can improve training speed by removing some features while having a minimum effect on model accuracy.
What can you do?
Eliminate features that are highly correlated to the output labels.
Combine highly co-dependent features into one representative feature.
Instead of feeding in each feature individually, average their values in batches of 3.
Remove the features that have null values for more than 50% of the training records.
Answer is Combine highly co-dependent features into one representative feature.
A: correlated to output means that feature can contribute a lot to the model. so not a good idea.
C: you need to run with almost same number, but you will iterate twice, once for averaging and second time to feed the averaged value.
D: removing features even if it 50% nulls is not good idea, unless you prove that it is not at all correlated to output. But this is nowhere so can remove.
Your company is performing data preprocessing for a learning algorithm in Google Cloud Dataflow. Numerous data logs are being are being generated during this step, and the team wants to analyze them. Due to the dynamic nature of the campaign, the data is growing exponentially every hour. The data scientists have written the following code to read the data for a new key features in the logs.
BigQueryIO.Read -
.named("ReadLogData")
.from("clouddataflow-readonly:samples.log_data")
You want to improve the performance of this data read.What should you do?
Specify the TableReference object in the code.
Use .fromQuery operation to read specific fields from the table.
Use of both the Google BigQuery TableSchema and TableFieldSchema classes.
Call a transform that returns TableRow objects, where each element in the PCollection represents a single row in the table.
Answer is Use .fromQuery operation to read specific fields from the table.
BigQueryIO.read.from() directly reads the whole table from BigQuery. This function exports the whole table to temporary files in Google Cloud Storage, where it will later be read from. This requires almost no computation, as it only performs an export job, and later Dataflow reads from GCS (not from BigQuery).
BigQueryIO.read.fromQuery() executes a query and then reads the results received after the query execution. Therefore, this function is more time-consuming, given that it requires that a query is first executed (which will incur in the corresponding economic and computational costs).
Reference:
https://cloud.google.com/bigquery/docs/best-practices-costs#avoid_select_
Your company is streaming real-time sensor data from their factory floor into Bigtable and they have noticed extremely poor performance.
How should the row key be redesigned to improve Bigtable performance on queries that populate real-time dashboards?
Use a row key of the form <timestamp>.
Use a row key of the form .
Use a row key of the form #.
Use a row key of the form >#<sensorid>#<timestamp>.
Answer is Use a row key of the form >#
Best practices of bigtable states that rowkey should not be only timestamp or have timestamp at starting. It’s better to have sensorid and timestamp as rowkey.
Reference:
https://cloud.google.com/bigtable/docs/schema-design
You are training a spam classifier. You notice that you are overfitting the training data.
Which three actions can you take to resolve this problem? (Choose three.)
Get more training examples
Reduce the number of training examples
Use a smaller set of features
Use a larger set of features
Increase the regularization parameters
F. Decrease the regularization parameters
Answers are; A. Get more training examples
C. Use a smaller set of features
E. Increase the regularization parameters
Prevent overfitting: less variables, regularisation, early ending on the training
Reference:
https://cloud.google.com/bigquery-ml/docs/preventing-overfitting
You have some data, which is shown in the graphic below. The two dimensions are X and Y, and the shade of each dot represents what class it is. You want to classify this data accurately using a linear algorithm. To do this you need to add a synthetic feature.
What should the value of that feature be?
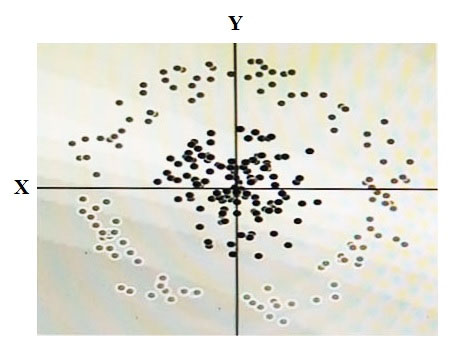
X^2+Y^2
X^2
Y^2
cos(X)
Answer is X^2+Y^2
Reference:
https://medium.com/@sachinkun21/using-a-linear-model-to-deal-with-nonlinear-dataset-c6ed0f7f3f51
You are building a data pipeline on Google Cloud. You need to prepare data using a casual method for a machine-learning process. You want to support a logistic regression model. You also need to monitor and adjust for null values, which must remain real-valued and cannot be removed.
What should you do?
Use Cloud Dataprep to find null values in sample source data. Convert all nulls to "˜none' using a Cloud Dataproc job.
Use Cloud Dataprep to find null values in sample source data. Convert all nulls to 0 using a Cloud Dataprep job.
Use Cloud Dataflow to find null values in sample source data. Convert all nulls to "˜none' using a Cloud Dataprep job.
Use Cloud Dataflow to find null values in sample source data. Convert all nulls to 0 using a custom script.
Answer is Use Cloud Dataprep to find null values in sample source data. Convert all nulls to 0 using a Cloud Dataprep job.
Key phrases are "casual method", "need to replace null with real values", "logistic regression". Logistic regression works on numbers. Null need to be replaced with a number. And Cloud dataprep is best casual tool out of given options.
You are developing an application that uses a recommendation engine on Google Cloud. Your solution should display new videos to customers based on past views. Your solution needs to generate labels for the entities in videos that the customer has viewed. Your design must be able to provide very fast filtering suggestions based on data from other customer preferences on several TB of data.
What should you do?
Build and train a complex classification model with Spark MLlib to generate labels and filter the results. Deploy the models using Cloud Dataproc. Call the model from your application.
Build and train a classification model with Spark MLlib to generate labels. Build and train a second classification model with Spark MLlib to filter results to match customer preferences. Deploy the models using Cloud Dataproc. Call the models from your application.
Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud Bigtable, and filter the predicted labels to match the user's viewing history to generate preferences.
Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud SQL, and join and filter the predicted labels to match the user's viewing history to generate preferences.
Answer is Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud Bigtable, and filter the predicted labels to match the user's viewing history to generate preferences.
1. Rather than building a new model - it is better to use Google provide APIs, here - Google Video Intelligence. So option A and B rules out
2. Between SQL and Bigtable - Bigtable is the better option as Bigtable support row-key filtering. Joining the filters is not required.
Reference:
https://cloud.google.com/video-intelligence/docs/feature-label-detection